HOG
HOG – histogram of oriented gradients
Soler et al. (2018) have proposed the correlation of gradient directions as a useful tool to compare astronomical images. This has some similarity to template matching and RHT analysis in that analysis is based on local quantities that are estimated at each pixel position. This time that local quantity is the local gradient, and especially the gradient direction, estimated from the pixel values in a small environment around each pixel position. Routines for HOG analysis can be found in the GitHub repository of Juan Soler.
We wrote a version, just for the comparison of two images, using Python and OpenCL. We are using two kernels. The first one does the combined smoothing and gradient estimation. This is a single operation that corresponds to the convolution of the image with derivatives of the convolving Gaussian beam. This is done in real space, extending the averaging of pixel values up to a distance of 5 standard deviations. In addition to gradients, HOG also includes calculation of some circular statistics. In the original Python version this relies on another Python library, namely pycircstat . The statistics are based on the summation of some quantities over the maps. We wrote this using another kernel where each work item calculates partial sums. These are then transferred to host (the main Python program) that sums these up.
We tested this on a pair of images that had an original size of 512 × 512 pixels but which in the test were scaled to sizes between 256×256 and 8192 × 8192 pixels. The following picture compares the run times, with CPU and GPU, to the original Python code. The x-axis indicates the scaling of the image dimensions.
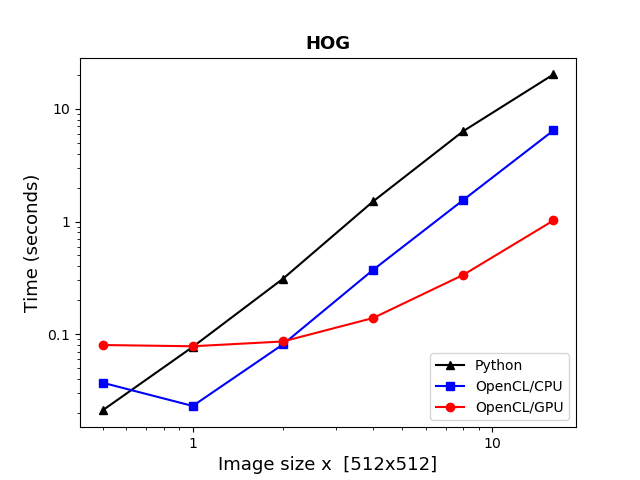
Because of the overheads of kernel compilations and data transfers, the OpenCL versions are for the 256×256 image slower than the original pure Python program. Above 512×512 pixels they overtake the original Python program and for sizes above 1024×1024 pixels GPU becomes faster than the CPU. By the time we reach the 8196×8196 image size, we have probably converged to the final ratio between the run times: CPU version is ~3 times and the GPU version ~20 times faster than the pure Python program.
For CPU the result is actually not so good. By using 6 CPU cores, instead of the one employed by the original Python programme, we have only gained a factor of three in the run time. We might have expected more than a factor of six, especially when moving from interpreted Python to compile kernel programs. At the largest image size, CPU is using some 4 seconds on the first kernel and some 1 second on the second kernel that is called twice during each run. The poor performance of the convolution/gradient kernel might be because of the decision to do the convolution in real space. Although the convolving Gaussian was here small (σ ~ one pixel), each gradient value still requires the summation over almost 100 pixels. The use of FFT (like in the case of the Python code) might be more efficient. The convolution is the most time-consuming part and is even in the case of the original Python program done via a compiled FFT library routine. This means that the Python overhead is not significant for the original program. GPU runs the first OpenCL kernel in 0.2 seconds instead of the 4 seconds it took for the CPU. The second kernel takes 0.13 seconds on the GPU and ~1.0 on CPU. However, just by looking at the second kernel, one can see that it is not going to be very fast on OpenCL. There is too little computation compared to the amount of data that needs to be shifted between the host and the device.
In summary, this exercise was partially successful. This OpenCL implementation is not very useful if one is analysing only small maps. On the other hand, with 10k images and larger, the ×20 speedup of the GPU version is significant.
The test was run on a laptop with a six core i7-8700K CPU running at 3.70 GHz and with an Nvidia GTX-1080 GPU. The runs were made with the script test_HOG.py that can be found at GitHub , in the TM directory.